
TL;DR – Create a custom proxy to make sure you know how the old system behaves and can transition off it in a controlled manner.
A couple of weeks back I held a talk at JavaZone about replacing legacy systems (Norwegian only, sorry). One of the techniques I talked about that seemed to spark an interest was creating a custom proxy to take control and figure out what the old system does.
Not a dedicated proxy like Nginx or Apache, a custom proxy in the language and technology you are comfortable with. It can ease the replacement and transition a lot.
For us that was KTor Server+Client.
What?
When you have a system with a Webapp, Mobileapp and API like this:
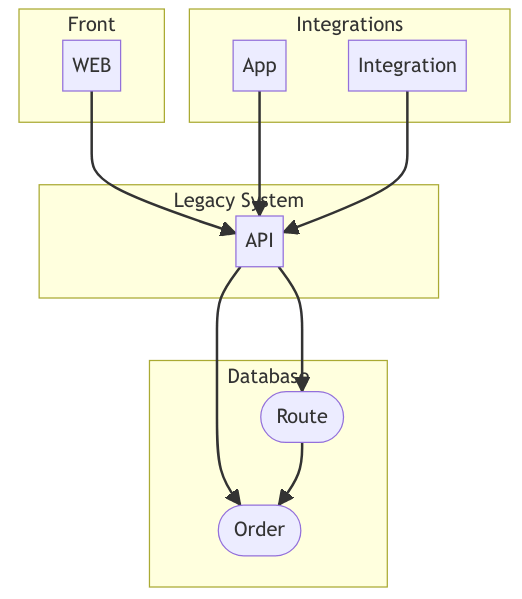
You can take control of the system by introducing a proxy like this:
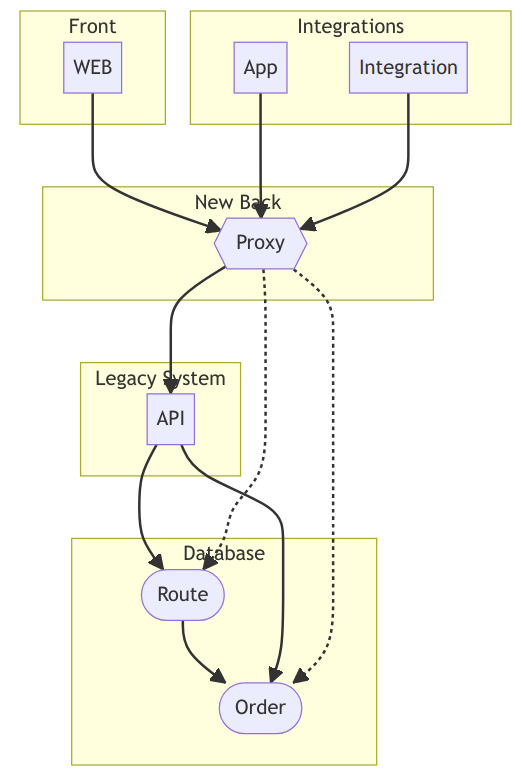
Simple as that. 😉 HTTP request in, HTTP request out, receive response and send response back to the source. A bit of fiddling around, but you essentially copy everything forward and back. Headers, Method, response codes and of course body.
The figure above also shows how we used the proxy to double check some data results in the DB before switching out the legacy system (the dotted lines).
Why?
By creating a custom proxy you can monitor, log, analyze and even compare results. All in your preferred development language.
When you gain insights into how your system is working, you can manage which parts controls and receives each call.
Wan’t to switch over based on user-id? That’s a simple conditional statement in your proxy code.
Switch gradually based on endpoints? Even easier, just change which system is the recipient for your call.
Subscribe new content:
How?
We used KTor Server+Client because it made it easier to know that coroutines were handled correctly but you could also use OKHttp as a client if you wanted.
Be careful with big payloads though, stream the results as a default, and only load the body into memory if you know the size and actually need to analyze or modify (don’t) it.
I don’t have the proxy as an example myself but this doesn’t look like a bad starting point: https://github.com/ranbims/ktor-server-proxy/blob/main/src/main/kotlin/org/ranbi/HttpProxy.kt
No HTTP?
Yeah, that’s harder. But still just streams of bytes back and forth. Even Cobol Copybooks has a format that can be parsed. 🙂
Happy migrating 😉
What’s your best techniques for migrating off legacy systems?